Webとデータベースの連携によって、 クライアント・サーバ型のシステムを容易に構築することができる。 今回はこの簡単な応用例として履修申告システムをとりあげ、 その作成法とパフォーマンス上の注意点、 さらに現行の履修申告システムの性能上の問題点などについて考察する。
キーワード:3階層型クライアント・サーバ・システム、WWW、 ブラウザ、JavaScript、RDB、SQL
事の起こりは平成10年4月の履修申告の時であった。 この時から山梨大学では、 学生の科目履修の申告に際して従来行っていたOCRによる入力方式から、 学内の教室や研究室からWebブラウザの画面を通じて履修科目を申告するという、 全国でも類をみない革新的な方法に移行した。 これにより入力ミスが減り、 データ処理の自動化によって履修申告の大幅な効率改善が見込まれるはずだった。 関係者の誰もが注目する中、全学で200台以上の端末を用意して履修申告が開始されたが、 学内の大多数が知っている通り、結果は惨憺たるものであった。 サーバのレスポンスが非常に悪く申告途中でのタイムアウトが相次ぎ、 割り当てられた時間内に申告を終了できない学生が相次いだ。 さらにはサーバのレスポンスを待つために保持しなければならないクライアントの接続数の異常な増加によって、 ファイアウォールがダウンしてしまうという事態に陥った。 いつ終わるとも知れない申告処理に苛立ち、あるいは絶望する学生で教室は埋まり、 それを必死になだめようとする教官とで正に修羅場となった。 このように最初の履修申告の試みは、 学生にとっても担当教職員にとっても非常に苦い経験となった。
しかし人間は失敗から学ぶことが重要である。 このWebによる履修申告システムの大惨事は、 Webとデータベースの連携したクライアント・サーバ型システムを構築する際に注意すべき点は何なのかという疑問を残した。 ここでは現在の履修申告システムの持つ様々な問題点のうち、 システムそのものの存在意義や運用上の問題点、 あるいは画面のインタフェースの使いにくさなどについては触れず。 純粋に技術的な観点からパフォーマンス上の問題点について考察する。
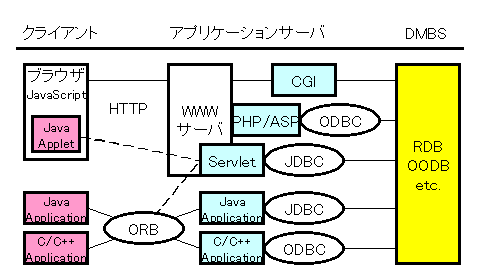
従来の単純なクライアント・サーバ型では、 システム全体はサーバとクライアントの2層から構成される。 これに対して最近は3層型のシステムで構築するケースが多くなってきている。 3層型ではサーバをアプリケーションサーバとデータベースサーバに別け、 2層型に比べて柔軟なシステムの構成をとっている。 アプリケーションサーバの部分は一般的にミドルウェアと呼ばれるもので置き換えられる場合もある。 3層型にすることによってデータとビジネスロジックの分離、 データベース負荷の分散(複数のデータベースサーバの利用も可能になる)、 クライアントの負荷軽減などが行える。 またクライアントにWebブラウザなどを利用できるようにすれば、 様々なプラットフォーム上で利用可能になる。 またシステムの構成方法が柔軟になり変化に対応しやすい一方、 自由度が高いぶん役割分担などを十分に検討する必要がある。
図1:3階層型クライアント・サーバ型システムの構成例
図1にシステム構成の例を示す。 クライアント、アプリケーションサーバ、 データベースサーバにどのような技術を利用するかによって、 それぞれの間でのインタフェースや通信プロトコルは変わってくる。 またクライアントとアプリケーションサーバ間、 アプリケーションサーバとデータベースサーバ間での役割分担なども、 構成の自由度が高いので設計者の力量に応じて様々なやり方が許される。 ある種の処理はクライアントで行うこともできればアプリケーションサーバが行うこともできる。 また例えばアプリケーションサーバの処理の一部をデータベースサーバ側の Stored Procedure で行うことも可能であろう。 システム設計者は採用する技術や各コンポーネントのパフォーマンス、 運用形態などを総合的に判断して最適な組合わせを決定する。 またシステムの拡張性や汎用性を高め将来性を重要視するならば、 特定のプラットフォームに依存する技術を避けることが賢明である。
まず履修申告システムを試作するに当っては以下の点に留意した。
その結果として以下のソフトウェアツールを利用することとした。 実験の段階でのバージョンと共に、 99年2月の段階での最新版のバージョンも括弧内に示した。
PostgreSQLは多くのUNIX環境およびWindowsNT上で利用可能な、 フリーなリレーショナル・データベース(以下RDB)である。 Apacheは世界中でもっとも広く使われているWebサーバであり、 多くのUNIX環境およびWindowsNT上でフリーに利用可能である。 PHP/FIはWebサーバ上で利用可能なスクリプト言語で、 PostgreSQLをはじめとする多くのRDBとのインタフェースを提供する。 クライアントにNetsacape NavigatorとJavaScriptを利用するのは、 これらが非常に多くのプラットフォーム上でフリーに利用可能であることと、 総合情報処理センターの情報処理教室ですでに多数の端末上にインストールされていたからである。 クライアント側で実行するプログラムに関してはJavaを利用しても良かったが、 履修申告程度の処理であればJavaScriptの機能で十分であるし、 実験段階ではまだクライアントのJavaVMのバージョンが若干旧かった。
計算機資源上の都合からアプリケーションサーバとデータベースサーバは、 同一のマシン上で動かすことにした。 マシンは128MBのメモリを搭載したUltra Sparc Creator1で、 OSはSolaris 2.6である。 履修申告用に実際に使われているサーバは、 1GBのメモリとCPUにPentiumProを4つ搭載している。 これはSPECint(rate)で比較したCPUの性能上では、 今回の実験環境の約3倍の性能である。 クライアントはPentiumII 233MHz、メモリ64MBのWindowsNTマシンである。
まずRDBであるPostgreSQLの基本的な性能を評価した。 ここでは単純な2階層型のシステムを構成し、 Javaでクライアントを記述を記述した。 データベースサーバであるPostgreSQLとはJDBCを用いてネットワーク経由で接続した。 JavaクライアントはSolaris 2.6が稼働するマシン上で動かした。 評価した内容は、 クライアントとサーバの接続のオーバーヘッド、 データベースからの単純な読み出し(SELECT)性能、 データベースへの単純な書き込み(UPDATE)性能、 である。 テストではサーバに接続しSQLのSELECTまたはUPDATEを、 検索キーを変えて1000回繰り返した。 1クライアントではサーバの負荷がピークに達しないため、 必要に応じて複数のクライアントを同時に接続して評価した。 SELECTおよびUPDATEリクエスト1件毎に毎回接続と切断を行った場合と、 接続してから1000回リクエストを処理して切断する場合を評価し、 その違いによってサーバとの接続のオーバーヘッドを評価することにした。 表中の数値はサーバが1秒間に処理できたリクエスト件数である。
使用したTABLEには主キー以外に25の項目を持つレコードを5000ほど作った。 25というのは月曜から金曜までの1から5時限目までのデータ、 5000というのは履修申告を行う学生数などを考慮して決めた。 データベースに対して発行したSQLのうち、 SELECT文は以下のようなものである。
SELECT * FROM table WHERE key = value
またUPDATE文は以下のようなものである。
UPDATE table SET var0=val0, ... , var24=val24 WHERE key = value
表1: PostgreSQLの性能評価
| 毎回接続 | 一度接続 | |
|---|---|---|
| 読み出し(SELECT) | 6.6 件/秒 | 30 件/秒 |
| 更新(UPDATE) | 2.4 件/秒 | 8 件/秒 |
この結果から、データベースへの書き込みは読み出しに比べてかなり遅いことがわかる。 またサーバとの接続のオーバーヘッドが大きいこともわかる。 これは大体どのRDBでも同様の傾向にあると想像される。 接続のオーバーヘッドを最小限にするためには、 アプリケーションサーバ側でデータベースサーバとの接続を保持することが重要である。 Webサーバ上で利用可能なスクリプト言語の中にはこのような永続的接続を提供するものもあるが、 残念ながら今回実験に利用したPHP/FI 2.0にはこのような機能は含まれていない。 後継バージョンのPHP 3.0では提供されているらしいので、 今から構築する場合にはそれを利用してパフォーマンスをあげることができるはずである。
履修申告システムでは各学生は曜日・時限毎に履修可能な科目の一覧を示され、 その中から履修したい科目を選んでゆく。 一つの曜日・時限(例えば水曜の3限)がブラウザで1ページ単位に表示され、 そこにその時限で履修可能な科目の一覧表が表示される。 その中から科目を選択して別の時限へ移ることを繰り返して最終的に全ての履修科目を選び、 確認したうえで最終的に登録を行う。 これはちょうどオンラインショッピングに似ている。 客は各棚を訪れて気に入ったものがあれば買い物カゴにいれる。 必要な棚から欲しいものを全てカゴにいれたら最後にレジで清算するわけである。 レジでの清算が申告登録に相当する。
その際に買い物カゴに相当する情報をどのように処理するかが問題となる。 Webではクライアントとサーバはページ移動の度に接続が切れるので、 何らかの方法で今まで選択した科目の一覧を保持しておかなければならない。 いわゆるトランザクション管理である。 これを実現するにはHTMLファイル中のHidden Formsを使う方法と、 ブラウザのCookiesを利用する方法が一般的である。 ここでは利便性の点からCookiesを利用してトランザクションを実現することにする。 ただしCookiesには1つのCookiesあたり保持できるデータが4KB以下、 1つのサーバ当り20個までのCookiesしか設定できないという制限もある。 試作した履修申告システムで扱うデータに関しては、 2次申告で科目数が増えた場合を考慮してもこの容量制限は全く問題なかった。
またCookiesは文字列データで、 クライアント側で読み出しと書き込みも可能である。 そのため例えばユーザのパスワードなどを直接わかる形でCookiesに保持しておくようなことは避けなければならない。 また万一ユーザ側で勝手にCookiesを書き換えるなどの改竄行為があった場合を想定し、 Cookiesデータの整合性を確認する仕組みを考えておく必要がある。 このためには例えばPHP/FIをはじめ多くのサーバスクリプト言語でサポートされている、 MD5による署名などを利用すれば良い。 今回の実験でもMD5に基づく方法を利用することとした。 ここで注意が必要なのはMD5の値は誰でも計算できるので、 改竄されたデータのMD5値をクライアント側で書き込まれたら、 サーバからは見掛け上正しいデータと区別がつかないということである。 このため単純にMD5値を使うのでなく、 クライアント側では知り得ない別の簡単な演算と組み合わせて使う必要がある。
上述のような点を考慮して実際に履修申告システムを試作してみた。 PHP/FIはエラーメッセージの出力が分かりやすいのでデバッグがしやすく、 このようなWebサーバ用のスクリプト言語プログラミングの初心者である筆者でも、 1週間程度で初期段階の試作をすることができた。 試作履修申告システムではクライアントから見た申告処理は、 以下のような流れとなる。
以上の流れは実際の申告処理とほぼ同じであるが、 実際の申告処理の際には科目選択と最終申告の際に幾つかの正当性のチェックを行っているはずである。 それは例えばすでに修得済みの単位などと見比べての履修可能性であったり、 複数の時限にまたがる科目同士のチェックであったり、 組合わせて取らなければならない科目のチェックなどもあるかもしれない。 今回の試作システムではこういったチェックに必要となる実際の科目のデータを入手していないので、 これらのチェックは含まれていない。 これらのチェック処理を行った場合のパフォーマンスについては別途検討する必要があるが、 実はクライアント側で行える処理も多く、 うまく実装すれば全体としてパフォーマンスをほとんど損なうことなく実現できると考えている。
実際の履修申告システムでは200人程度の学生が同時に申告を行った場合に、 月曜1限から金曜5限までの25コマ分を申告するのに30分程度で済むことという目標がある。 この目標と同じ条件でテストするためには200台の端末に200人を動員しなければならないわけだが、 試作システムのテストのためにそれを行うことは不可能である。 そこで今回は少ない人手(多くの場合は私一人)でそれに近い状況を作り出すために、 以下のようにクライアント側で実行するJavaScriptプログラムを工夫した。 すなわち一人の人間で200人分の画面を処理するのは不可能なので、 クライアント側ではサーバへの応答を自動的に行うことにした。 サーバがクライアントに送りつけるHTMLデータ中のJavaScriptの中に、 指定された時間内にある関数を自動実行するプログラムを埋め込んでおく。 このプログラムをサーバ側で適切に用意することで、 自動的に適切な科目を候補から選択して次の時限に移動したりすることが可能になる。
|
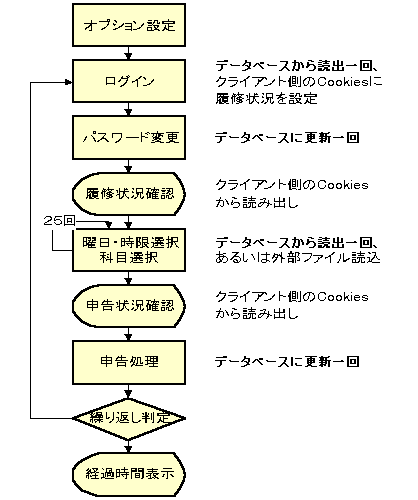
図2:履修申告ベンチマークの処理手順
試作システムのベンチマークのための処理手順を図2に示す。 自動実行開始時に応答時間をはじめとする幾つかのパラメータを選び、 ボタンを押すとあとは自動的にログイン、パスワード変更、 履修状況確認から申告処理までを全て自動的に行い、 最後に経過時間を表示する。 実際にはさらにこれらの一連の処理を指定された回数繰り返すようにした。 また自動応答時間をゼロにすればクライアントは瞬時に返答するので、 サーバにとっては非常に手強い相手となる。 このように設定したうえで数台の端末のうえで同時にクライアントを起動して複数回の申告処理を行い、 全体にかかった時間とサーバの負荷状況を測定した。
まずは3台のクライアントを起動し、 サーバへの応答時間をゼロに設定して3台同時に複数回走らせてみた。 申告1回当りデータベースサーバにはSELECTを26回、UPDATEを2回行う計算になる。 その結果1クライアント当り1回の申告に要する時間は14.4秒であった。 この時のサーバの負荷はほぼ100%に近い状況であった。 サーバのスループットが落ちなければ200人分を処理するのに16分程度要することになる。 これはマシンの性能の違いを考慮すれば実際の申告システムに比べても数倍は性能がよいことになる。 しかしこれではまだ十分に高速とは思えずパフォーマンスの改善を試みることにした。
まずベンチマーク実行時にサーバ上のプロセスの状態を見て分かったのは、 Webサーバのスクリプト実行に比べてデータベース処理の方が圧倒的に時間がかかっている、ということである。 PHP/FI 2.0ではWebサーバとデータベースサーバは永続的な接続を保てないため、 SELECTを1回実行する度に毎回接続を行っている。 PostgreSQLの性能評価の結果からも明らかなように、 この部分からくるパフォーマンスのロスは大きい。 そこでこの部分の改善をまず検討した。 まず考えてみれば曜日・時限毎に毎回行っているSELECTは、 その曜日・時限での履修可能科目の一覧を検索するためのものであり、 これらは読み出し専用のデータである。 ならば書込みが行われるユーザのパスワードや申告科目などと同じデータベースに格納する必要はなく、 もっと速やかに読み出せる仕組みを考えた方が良いはずである。 そこで今回はこれらのデータをPostgreSQLの外に出し、 各ユーザの各曜日・時限毎に1つのファイルとしてJavaScriptで読める形式、 またHTMLの表として整形されたデータとしてテキストで保存した。 これにより各曜日・時限での履修可能科目の一覧表を作るためには、 毎回データベースサーバを検索する必要はなくなり、 表の部分に対応するファイルをそのままその部分に挿入すれば良くなった。 これによってデータベースサーバへのアクセスは激減し、 全体のパフォーマンスは劇的に改善された。 ただしそのかわりに実際にこれらのデータを申告前に全て用意しておかなければならない。 これはデータベースから実行時に検索していた処理を、 あらかじめ前処理しておくことに他ならない。
上記の改善を行った上で再びテストを行った。 サーバのパフォーマンスが上がったことから、 今度はクライアントは10台同時に起動した。 クライアント側の応答時間をゼロにして同時に実行させたところ、 申告1回当りに要する時間は平均9秒であった。 これは200人分を処理するのに3分かかる計算である。 1ユーザ当りに要しているサーバの計算時間は約1秒で、 この1秒間でWebサーバは約30ページ分の画面を生成してクライアントに送りつけていることになる。 またこの時のサーバの負荷は約70%であった。 一人のユーザが25コマ分の科目を3分で申告するためには、 ログインから最終申告までに通過する28画面分を、 1画面当り平均6秒程度で応答しなければならないことになる。 ログインとパスワード変更の際にはキーボードからの入力が必要になるので、 かなりの時間を消費する。 最終確認の際にもある程度の時間を消費するし、 ユーザの交代に要する時間も生じるので、 一日を平均して一人3分で25コマ分を申告するのは至難の業である。 このためサーバの負荷は実際にはもっとずっと少なくてすむはずである。 また上述のように実際の履修申告で使用されているサーバの性能は、 今回試作システムを構築したサーバの2〜3倍程度と推定される。 幾つかのチェックを追加したとしても、 ユーザへのレスポンスを瞬時に返すことができるはずである。
試作システムの構築と性能評価を行って残った大きな疑問は、 なぜ現行の履修申告システムは遅いのかということである。 システムの製作担当者から的確な返答がなかったので、 設計仕様書を見せてもらうことにしたところ疑問は氷解した。 現行システムにはパフォーマンス上の問題点が幾つかあることが分かった。 以下にそれらの幾つかについて説明する。
RDBを用いて何らかのシステムを構築する際には、 データベース内のデータの表現形式はシステムの機能や性能に大きな影響をもたらす。 悪い設計をしてしまったために使い物にならないシステムができてしまう例も多く、 日経コンピュータの特集「続・基幹系に変革のチャンス データベース構築の巧拙が命運握る」などでも大々的に取り上げられている。 RDBでは全てのデータ構造は表とそれらの関係で表現される。 論理レベルの設計段階では表の「正規化」を行いデータの冗長性や重複を排除し、 依存関係を明確にしてデータの矛盾が生じない構造を作り出す。 これは非常に重要なプロセスで、この段階でデータは複数の表に分割される。
こうして作られたデータ構造は論理的なモデルであり、 超高速なデータベースであればそのまま動くはずである。 しかし現実的にはデータベース側の様々な制約から十分なパフォーマンスが発揮できない。 そこでパフォーマンスを考慮して実際に使うための物理的なデータベースを設計しなければならない。 実際に良く行われるデータベースへのアクセスのパターンを考慮し、 論理的なデータベースの幾つかの表を統合したりデータの項目を重複して持つような形に戻したりする。 この過程は非正規化と呼ばれ、実用システムでは必ず行う必要があるとされている。
しかし設計仕様書を見る限りではこのような非正規化は行われておらず、 論理設計の段階に近い形式で運用されている。 その結果として頻繁に行われるある種の検索においても、 まずある表からあるキーで検索し、 その結果から別の表の別のキーを検索することを繰り返すなど、 多段階の検索を行う必要がある。 頻繁に検索するデータは非正規化によって一つの表にまとめておき、 一回の検索で取り出せるような工夫をしておく必要があるはずである。 上述のように試作システムでは適切な前処理をすることによって、 その一回の検索すら省いてしまえる場合が多いことがわかった。 データ構造の非正規化による再設計が必要であろう。
オンラインショッピングの例で述べた通り、 履修申告の際にはユーザとのトランザクションを管理する必要がある。 試作システムではそれをブラウザのCookiesで実現し良好なパフォーマンスが得られた。 実際Cookiesを用いた場合と全くトランザクション管理をしなかった場合でのサーバの処理速度の違いはほとんどなかった。 しかし設計仕様書を見る限り現行の履修申告システムでは、 この部分の処理はデータベース側で独自に行っている。 買い物カゴに相当するデータは全ユーザで共有されており、 ユーザはこの巨大な単一の買い物カゴに自分の名前を書いた品物を入れている。 申告作業中は全ユーザがこの単一の買い物カゴに対して頻繁に読み書きを行う。 あるユーザが書き込んでいる間は別のユーザには読み出しも書き込みも行えないロック状態になっているそうなので、 この部分でパフォーマンスが大幅に落ちているものと思われる。 Cookiesなどの利用が効果的だと考えるがデータベースだけで解決する方法として、 せめてユーザ毎に買い物カゴを用意するぐらいは最初から行えていないのが不思議である。 個人的にはこの部分が現行システムの性能低下の最大の要因となっていると考える。
上の2つが性能低下に相当寄与していると思われるので、 まずその部分の改善をしなければそれ以外の部分での改善について現段階で論じても、 あまり意味はないかも知れない。 しかし一応幾つか気になって点について触れておく。 例えば現在サーバ側で行っている処理のいくつかは、 クライアント側で行わせることができる。 またHTMLデータ作成の際に動的に生成しなければならない部分と、 静的ファイルとして用意しておける部分などをもっと整理して切り分ければ、 アプリケーションサーバ側の処理はすっきりしたものにできる。 読み出し専用のデータなどはデータベースサーバに入れておく必要すらないと思われるものもある。
いずれにせよ現行システムは設計の基本的な部分で性能のことを十分に考慮したとは思えない作りとなっている。 個人的にはこれでも動いているのが不思議という印象を受けている。 ハード面の増強以前にやっておかなければならないことがまだまだある。
以上Webとデータベースの連携によるクライアント・サーバ型システムの構築の例として、 履修申告システムを試作してその性能評価を行った。 試作システムでは十分なパフォーマンスが得られたが、 さらなるパフォーマンスアップのためにまだまだ性能をあげる余地はある。 試作段階で利用したソフトウェアも最新版では機能・性能共に様々に強化されており、 それらを試みるのも面白いだろう。 現段階では十分に性能評価してはいないが、 JavaScript1.2による外部ファイルスクリプトの利用、 PHP3による永続的データベース接続、 JServのThread Poolの利用なども効果的と考えられる。
一方で試作システムでは申告科目などの細かいチェックは行っていない。 そのためには実際のデータかそれに近い形のデータを用意しなければならないが、 現段階ではそれは無理である。 また試作システム作成中に気付いたのは、 クライアント側のJavaScriptでの日本語処理の問題である。 日本語処理できるコードや処理結果がOSやブラウザでずいぶん違うのである。 もともとJavaScriptは日本語に十分対応しているとは言えないので、 実用システムを構築する際には利用する環境に応じて様々な工夫が必要になる。 そういう意味ではこれからはJavaの利用などが良いのかもしれない。
実用化という点からするとセキュリティの観点から、 クライアントとアプリケーションサーバの通信の暗号化などは重要であろう。 これはSSLなどの技術を利用するのが現実的だと思われるが、 それによってアプリケーションサーバのパフォーマンスがどの程度影響されるかは現段階では不明である。 現行サーバのパフォーマンスが現実的なレベルまで改善された段階で検討する必要があるだろう。
最後に試作システムを構築するきっかけを作ってくれた履修申告システムの関係者の方々、 実験を手伝ってくれた山梨大学総合情報処理センターの小林睦美さんに感謝します。