[研究報告の目次へ戻る]
PSC'99(Parallel Software Contest'99)報告〜製作したプログラムについて〜
山梨大学工学部電子情報工学科Kクラス3年
T97E017H
石原 誠
今回のソフトウエアコンテスト(PSC'99)はJSPP'99(Joint Symposium on Parallel Processing)の中で併設されている並列ソフトウエアのコンテストで、各企業から提供される並列マシンを使って問題を解決する。
ちなみに今回は以下のマシンが使用可能であった。
- Cenju-4(NEC)
- SR2201(日立)
- AP3000(富士通)
- Exemplar(NKK)
- RS/6000sp(日本IBM)
- Enterprise(サンマイクロシステムズ)
参加者は問題解決をするための並列プログラムを作成し、それで解いた実行結果から、順位を各マシンごとに決める。このコンテストは今回で6回目で、過去の問題には、ナップザック問題(NP−完全問題)などがあり、前回は疎行列連立一次方程式の解を求めることであった。
私は、前回もこのプログラムコンテスト(PSC’98)に三人(山形大学工
学部生、東京工科大学生 共に高校時代の同級生)で参加した。去年はCenju-
3部門(NEC)のみにエントリー。三人で始めたつもりだったが、学校が違っ
たりして連絡を取ることが難しく、実質一人で開発することとなった。また、
プログラムを提出しようとしたが、開発開始がプログラム提出日間近で出せる状態ではなかった。
前回の状況を振り返ると以下のことがいえる。
- 大掛かりなソフトウエア制作は一人で行なうことが難儀である。複数人での開発が望ましい。
- 開発を複数人でする場合はメンバー構成は学内で組んだほうが良い。
- 問題が出題されたと同時に開発を始めなければソフトウエアを作り上げることは出来ない。
ソフトウエアをまともに作ったことが無かったので是非一本くらいまともなソフトウエアを開発したかった。
では並列計算機とは何なのか、並列計算機とはどのような利点があるのかを簡略に説明したい。
並列計算機は多数のプロセッサが互いに通信し協調しあいながら、一つの大きな問題を細分割して超高速に解決することの出来る計算機(群)である。並列計算機は並列に物事を処理出来る。
例えとして、資料の製本をあげる。
机の上に100種類の紙が並んでいる。100種類の紙はそれぞれ100枚の束になっていて全てで一万枚である。人間が100種の紙を束から全種類順番に取っていってそれをホッチキスでとめて製本する。製本には1冊につき1分かかるとする。
一人ぼっちで100冊全て製本すると単純計算でも100分かかることになる。ところがこの仕事を10人で10冊ずつ製本することにすれば約10分で作業が終わる計算になる。このような単純作業は「一人よりもたくさん」のほうが時間を短縮することが出来るというわけである。しかし問題が無いわけではない、100人以上でこの作業を行なうと仕事からあふれてしまう人が出て来たり余計に時間が掛かったりすることがある。
では上記の例を並列計算機に置き換えてみよう。
製本する人数はプロセッサ数に相当し1人で作業していたものが10人で作業するということは1プロセッサだったものが10プロセッサになるのである。
一人当たりの製本する紙の枚数は1プロセッサ当たりのデータのメモリー使用量に相当し10000枚/1人という処理をしていたものが1000枚/1人になるのは1プロセッサあたりのデータ量が1MByteから100KByteに変化したことになる。
要するにデータを細分してしてたくさんのプロセッサで同時処理すれば速くな
るということである。
並列計算機にはメリットがあればデメリットもある。メリットは上記の通り細分データを同時処理することによって処理時間を短縮することが出来る。デメリットとしてはアルゴリズムを下手に選択するとシングルプロセッサの処理の方が速かったりする場合などがある。またあまりにも少ないデータ量に対しては通信時間のほうが処理時間よりも大きくなりあまり有効な処理とはいえなくなる。なお、並列計算機はプロセッサ間の通信時間がボトルネックとなる事があるので通信を多用すると時間がかかり処理の効率が下がる場合がある。
問題が公表されたのは4月に入ってからである。これは前回よりも少々遅い知らせだった。
さて今回の問題は、以下の通り提示された。

今回はベクトルのソーティング結果を返すpsc99()と言う関数を作成する。psc99()は問題の読みはじめから始めて結果を返す関数である。
解答のチェックは、専用の関数checkit()を用いて計算する。ソーティングされたリストが本当にソーティングされているかをチェックして昇順にソートされていえるとき1を返しそうでないときは0を返す。
順位の決定は関数psc99()にかかった時間とする。問題は予選問題と本選問題がある。本選問題は複数個与えられ、それらの実行時間の総和で、順位を決定する。
また、今回は与えられるベクトルのデータは並列計算機のメモリ使用量の35%以上を超えることはない。
これだけでは問題が何を言っているのかが分からない、私自身理解するのに時間を要した。ここで今回の問題を簡単に解説をする。
今回の問題の解説
今回私が受賞した部門の並列計算機「Cenju-4(せんじゅふぉー)」はNECが開発した並列計算機でPSC'99で初登場した(前回PSC'98はCenju-3)性能は以下の通りである
- プロセッサはVR10000(200MHz)。
- ノード台数は8〜1024台。
- 多段接続網。
- ノード間転送速度は200MB/sec×双方向
- UNIXベースのOS。
- 使用言語はMPICHとParalib/CJ4。
今回はCenju-4の中で総プロセッサ数が32個のものと総プロセッサ数が16
個のCenju-4がそれぞれ一台提供された。並列マシンでのソフトウエアの開発
方法を少し説明してみたい。まずは一般的な単プロセッサでのソフトウエア開
発をするのと同じように行なう。そこに並列処理専用の命令を付加する。その
ソースファイルを並列マシンを管理しているサーバ(e1という名前)に送る。
そこでコンパイルをするわけである。今回のCenju-4でのコンパイルはpsc99.c
というソースファイルでサーバに保存しておけばNECが提供してくれたMakeコ
マンドで行なうことが出来る。そして実行するわけである。実行コマンドは
cjsh -n 32 psc99
である。cjshは並列実行したいというときに使用すコマンド。-n 32オプションは32個のプロセッサを使用したいという要求を宣言する引数である。psc99と書いてあるところは実行したいファイル名である。プロセッサ数を-nオプションで要求しても他のジョブが仕事をして、自分の実行に-nで指定したプロセッサ数が確保できないときにはエラーとなって帰ってくる。
学内での開発環境を少し書いておく。Cenju-4にはIPアドレスの登録されているマシンからのtelnetが必要であったので今回はerida01をログインマシンとして登録をした。また、開発用マシンには24時間使えてしかもKKI(計算機室)と同じ環境のアシスト室doris02(現doris.ast.kki.yamanashi.ac.jp)を選んだ。
並列計算機には専用のライブラリが用意されている。Cenju-4でも並列ライブラリが以下のように二つ用意されている。
- MPI(Message Passing Interface)
- 並列処理用ライブラリのデファクトスタンダード。ほかの並列計算機にも搭載されていることが多い。
- Paralib/CJ4
- 前時代マシンCenju-3上のソフトウエア資産を継承するための互換ライブラリ、NEC独自のため他社のマシンに互換性がない。
- しかし、MPIよりも高速との噂。
今回は全マシンにエントリしていたので他マシンへの互換性の高いMPIで開発をした。
Cenju-4の概観図
開発をいざ始めようとしたがなかなかアルゴリズムを一から開発するのは難儀である。そこで今回、上記の問題を解決するために使用したアルゴリズムを提示する。これは「バイトニックソート」と呼ばれるソーティングで並列処理のソーティングではごく一般的なアルゴリズムであり、バイトニック(bitonic)≒双調な」列をソーティングするという事である。バイトニックと対照的な言葉として「モノトニック(monotonic)≒単調な、一本調子の」と言うものがある。
まず、ソーティングは配列を単調増加(減少)にする事である。単調な増加や減少になった配列のことをモノトニック列と呼ぶ。バイトニックソートは、ソーティングする際にモノトニックを二本(単調増加・単調減少一本ずつ)使ってそれをマージソートする。
バイトニック列の条件として以下のことが挙げられる。

バイトニックソートは二つの基本性質がある。基本性質は以下の通りである。

バイトニック列の条件は次の図によって視覚化される。
バイトニック列の条件の視覚化
バイトニック列基本性質を次の図によって示す。
バイトニック列の基本性質の視覚化バイトニック列の条件と基本性質を図示した。ここから実際にバイトニックソーティングアルゴリズムを使用してソーティングをしてみる。今回使用した並列マシンは32個ものプロセッサを使用していたのでその全てを実際に視覚化することは避け、ここに4つのプロセッサ(No.0・No.1・No.2・No.3)を例にとってソーティングをする。
プロセッサ(No.0〜No.3)にはそれぞれデータが含まれている。データの数は均等に配置してある。
ここで大切な事がある。それはソーティングスケジュールの問題である。次の行動を見越してソーティングの昇順・降順を決定する。また、バイトニック列の中から基本性質を使って大きい方のデータを取るか小さい方のデータを取るかも重要である。これは今回結構難しかったところである。間違えてソーティングすると時間が掛かるだけではなく間違えたソーティング結果となる。実際にソーティングをしてみる。
バイトニックソーティングの視覚化
ちなみにこのソーティングのオーダーは(log n)((log n)+1)/2回である。こ
れは並列ソーティングでは比較的小さいオーダーである。並列マシンではデー
タの送信がボトルネックになる場合が多い。送信回数が少ないこのソーティン
グのほうが送信回数の多いほかのソーティングよりも有利である。このアルゴ
リズムによって私のプログラムはソーティングに成功することが出来た。
とりあえずデータのソーティングはバイトニックソーティングで成功した。まだ少し締切りには時間があったので今度はチューニング(改良)を始めた。上記のバイトニックソーティングは基本的なことをしたまでのことでまだまだ改良の余地があった。そこで更なる高速化を目指し、今回2つの改良に着手した。それを説明したい。
- 改良その1.互いにコピーしてきたデータを比較するとき、最後まで比較をしない。
データが比較対象に値しなくなったとき、そこで比較することを止めてもかまわない。これはどういう事かと言うと、単純に「余計なことに時間を使わない」のである。
- 改良その2.データを操作してバイトニック列を得たときにいちいちクイックソートをしていたがバイトニック列をマージソートするほうが早い。
ここで、今回の改良点を表示する。
改良点を表示する
ソーティングの改良の視覚化
改良前と改良後では時間が数倍違う。もし今回の改良点を発見していなければ入賞もしてなかったであろう。改良その2に関しては「バイトニックソーティング」は又の名を「バイトニックマージソーティング」ぐらいだからマージソーティングするのは当たり前じゃないか、と某助教授が言っていた。
締切りは各マシンの部門ごとに決まっていた。アルゴリズムの改良を色々して
いたので今回提出が間に合った部門は締切りが一番遅かった「NEC-Cenju-4部
門」だけであった(1999年5月27日木曜日24時)。
今回は去年のような失敗を避けるために以下のような開発日程となった。
締め切り日まですべての土日はつぶして開発、締めきり一週間前からはアルバイトを休んで午前3時まで毎日開発をし、それ以外の平日はアルバイトを8時半で切り上げて9時半くらいから3時くらいまで開発を行った。
バイトニックソートで問題が解けたのは締切り1週間半前くらい、それまではまったく解けなかった。ソート結果が間違えていると(Result is invalid)という表示が出る。
改良1に気づいたのはその次の日ぐらいだったのだが、改良2に気がついたには締め切り直前だった。
改良2を直前に発見してしまった私は、改良2を実現するために開発に打ち込んだが、改良2はバグが多く、せっかく解けていた問題が(Result is invalid)になってしまった。
何も進展しないまま締め切り日の朝を迎えてしまい、どこにバグがあるかを捜し求めた。バグはプロセッサ中のデータがすべて同じデータのときにソートが不可能になっていることに気づき、それからはそのバグ修正に追われ、バグ修正が完了したのは締切り一時間前だった。
締めきり一時間前には開発マシン(Cenju-4)はネットワークが重かった。要するにみんなが締切りに追われていて一生懸命やっていると言うことである。コンパイルするのにも2分間ぐらいかかった。
ぎりぎりまでテストしていたので提出したのは締め切り10分前ぐらいだった。
いったいこのソーティングアルゴリズムで解いた問題はどのようなものかを示
すと。
- 予選問題12問
- 一問中のデータの大きさ、最大67,200,000・最小160,000
予選問題がすべて完走できると本選問題へと移る。この時完走と言うのは予選
問題をある程度の時間内で(各問30分程度)且つ、ソーティングしたデータがあっていることである。
- 本選問題5問
このデータの大きさはベクトルの二乗ノルムの数を言っているので実質的には
倍精度浮動小数点数(double型)でそれの4倍格納されていることとなる。よっ
て最大67,200,000ということは67,200,000×4で 268,800,000のデータが格納されている。
本選の問題を解いて実行時間と正確さを競った。実行の状況は主催者側が発表するまで分からない。結果が出るまでには時間が掛かった
そして5月28日には本選の結果がメールで来て、結果は以下の通りになった。
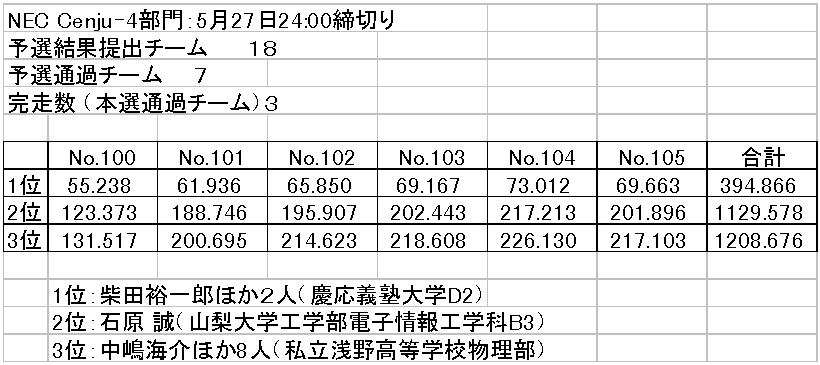
結果はCenju-4部門2位。驚くべき結果となり表彰式に出ることになった。
シンポジウムの会場は茨城県つくば市にある「つくば国際会議場(エポカルつ
くば)」で1999年6月9日から3日間行われた。
シンポジウムでは日本の並列処理分野の最高水準の話が聞けた。意味が分からないと言えばそれまでなのだが、この話が全て理解できるように努力すれば良いという目標が出来て大変有意義であった。
授賞式はたった15分で終わってしまった。ただ賞状をもらっただけであった。
去年まではスパークワークステーションなどが副賞となっていたが今回は各企
業の話し合いにより無しになった。その代わりと言っては何だがNECのC&C研究
所で実際に並列マシンを見せて頂く約束をとりつけた。
今回のソフトウエアコンテストを終えて思うことがいくつかある。
- 一人で開発することには限界を感じつつある。来年こそ複数人での開発を行ないたい。
- アシスト室が使えたことは私にとってとても有益であった。来年もこの部屋が使えれば幸いである。
- 今年は完走だけを目標とした消極的改良をしていたが来年は積極的な改良を試みたい。
- 来年は上を目指す。若しくは複数部門同時入賞を目指したい。
- 情報処理センターのshingenサーバが並列マシンだということを最近知った。来年はこのマシンをフルに利用して開発を進めたい。
今回のコンテストの結果はまずまずのものであると思った。しかし結果を見ると今回受賞した部門では私と一位の時間差が3倍以上ある。これを来年は何とかして縮める若しくは逆に上位に立って他を圧倒したい。
最後に、このコンテストでソフトウエアを開発することは精神的に重労働にであることに気づき大変勉強になった。今回の経験はこれからの私のソフトウエア開発に大いに役に立つと考えられる。
- 謝辞
このソフトウエアコンテストに際し、様々なお力添えをしていただいた工学部コンピュータ・メディア工学科美濃英俊助教授には大変感謝しています。ありがとうございました。また、開発に際し快く場所を提供して頂いたKKI-assistの皆様に感謝します。尚、毎日私のことを応援してくださった工学部コンピュータ?"<fィア工学科小林正樹助手(山崎研究室)にも感謝します。
- 参考文献
[研究報告の目次へ戻る]